
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Supabase is an open source Firebase alternative that helps you get started quickly with a backend. Supabase gets you started with a Postgres database, authentication, APIs and more. Thousands of developers use Supabase for all sizes of projects.
In this guide, we're going to walk through how you can anonymize sensitive data in your Supabase database with synthetic data for testing and rapid development using Neosync. Neosync is an open source synthetic data orchestration company that can create anonymized or synthetic data and sync it across all of your Supabase environments for better security, privacy and development.
If you haven't already done so, follow the Seeding your Supabase DB with Synthetic Data blog to get set up.
Let's jump in.
We're going to need a Supabase account and a Neosync account. If you don't already have those, we can get those here:
Now that we have our accounts, we can get this ball rolling. First, let's log into Supabase. If you already have a Supabase account then you can either create a new project or use an existing project. If you don't have a Supabase account then give your database a name, type in a password and select a region like below:
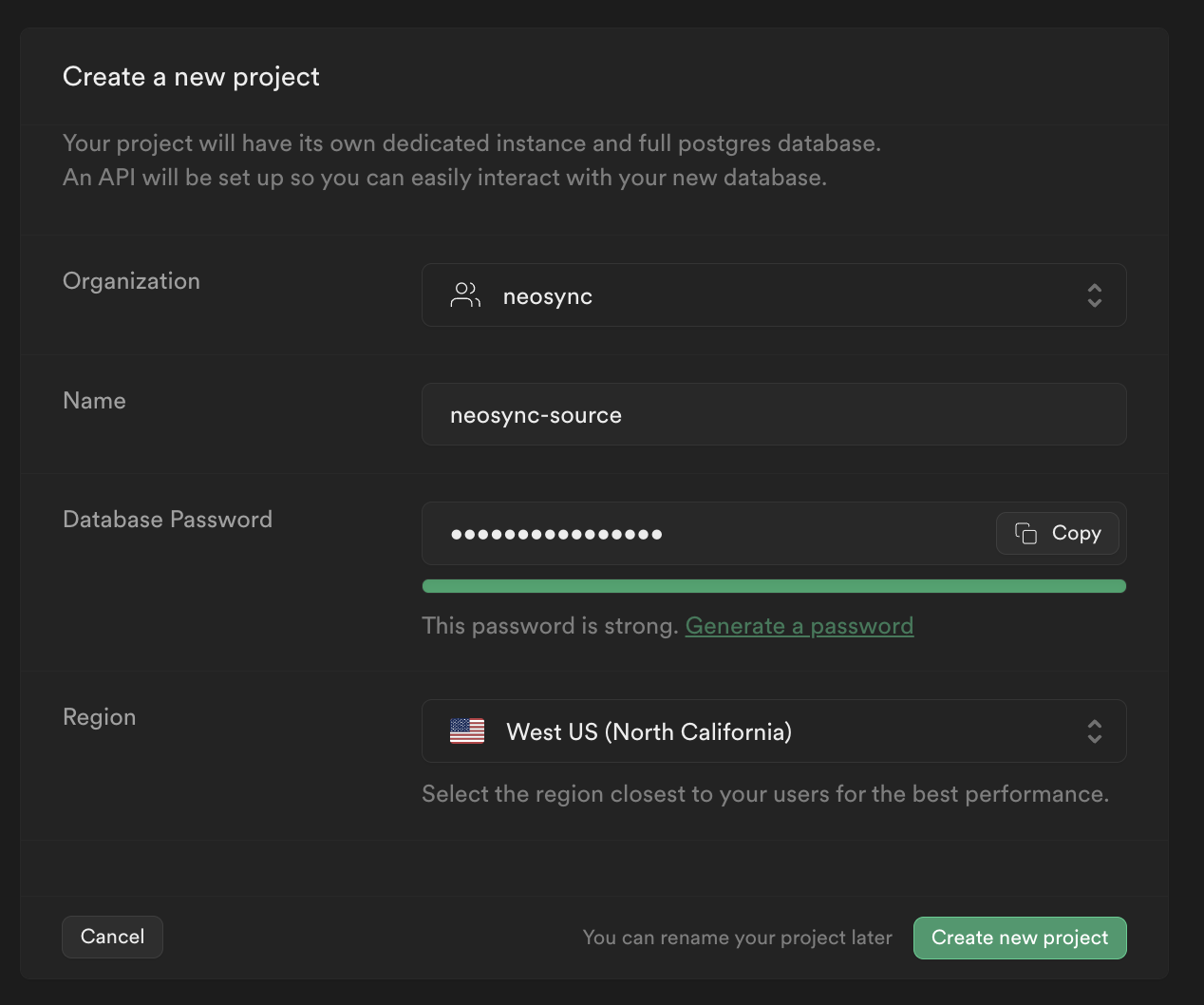
We'll need two separate databases to show data syncing from a source to a destination. We've already created one so let's create the other.
To create a new database, click on neosync-source on the top navigation bar and then click on + New project.
Go ahead and name this one neosync-dest, create a password and then click on Create new project.
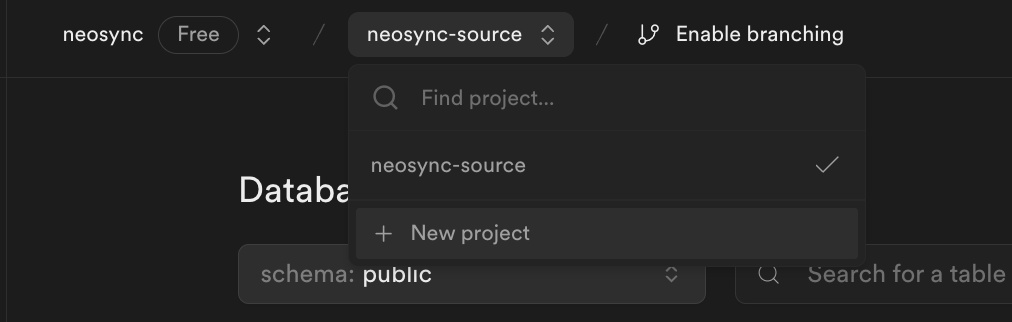
So now we have two databases: neosync-source will be our source and neosync-dest will be our destination database. I already have data in my neosync-source database but if you don't you follow our Seeding your Supabase DB with Synthetic Data blog to seed your database with data.
Next, we'll need to define our destination database schema.
At this point, your neosync-source project and database should have a schema so let's go ahead create our neosync-dest schema.
Let's navigate to SQL editor and create our table. Here is the SQL script I ran to create our table in the public schema. If you have the uuid() extension installed you can also set the id column to auto-generate those for you or you can use Neosync to generate them. Let's create our table.
CREATE TABLE public.users (
id UUID PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INTEGER NOT NULL
);We can do a quick sanity check by going to Database on the left hand nav menu and seeing that our table was successfully created.
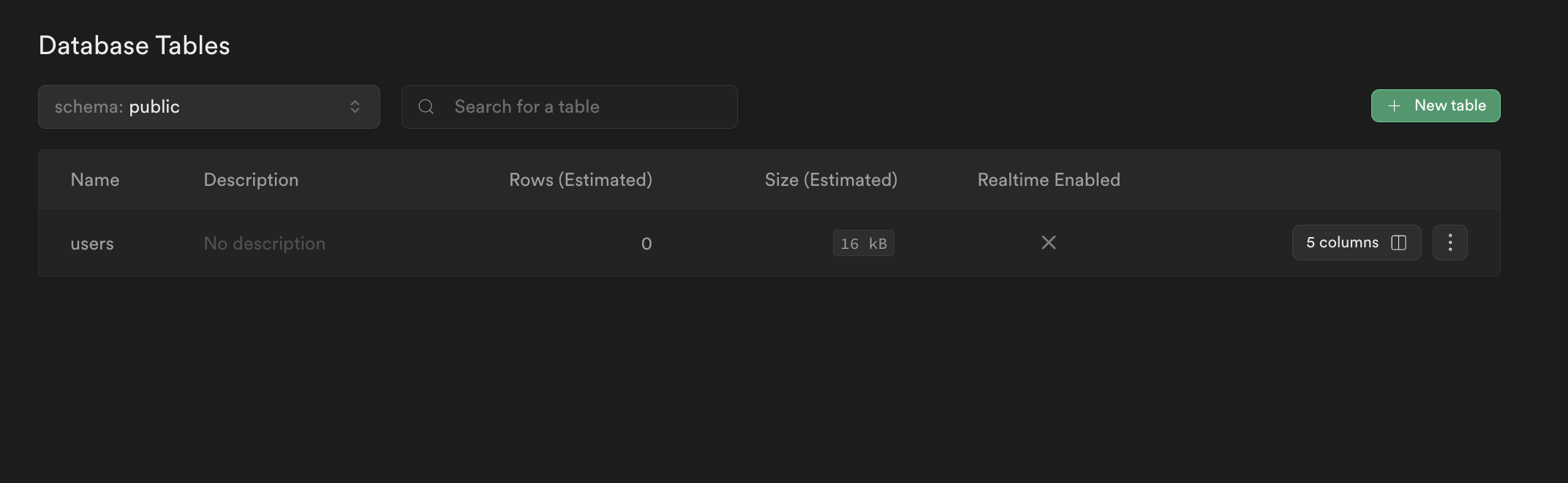
Nice!
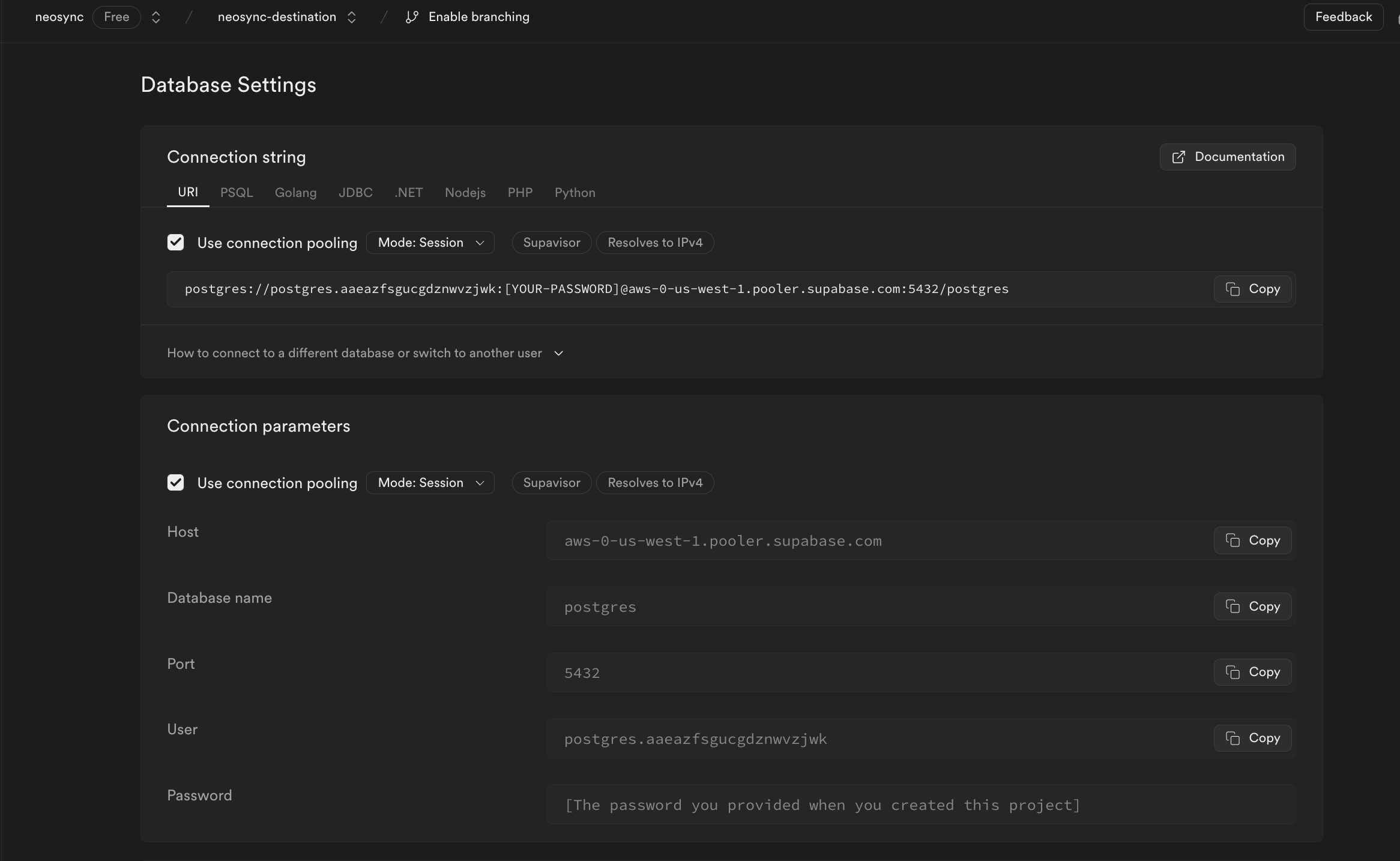
Nice! Okay, last step for Supabase. Let's get our connection string so we can connect to Supabase from Neosync. We can find our connection string by going to Project Settings then Database. Under the Connection parameters heading, you can find your connection parameters to connect to your database. Since we have already created our source database connection, we just need the neosync-dest Connection parameters.
Now that we're in Neosync, we'll want to first create connections to our Supabase database and then create a job to sync data. Let's get started.
Navigate over to Neosync and login. Once you're logged in, go to to Connections -> New Connection then click on Postgres. You can clone the existing source connection by clicking on the supabase-source connection and just updating the Username and Password or just create a new connection from scratch.
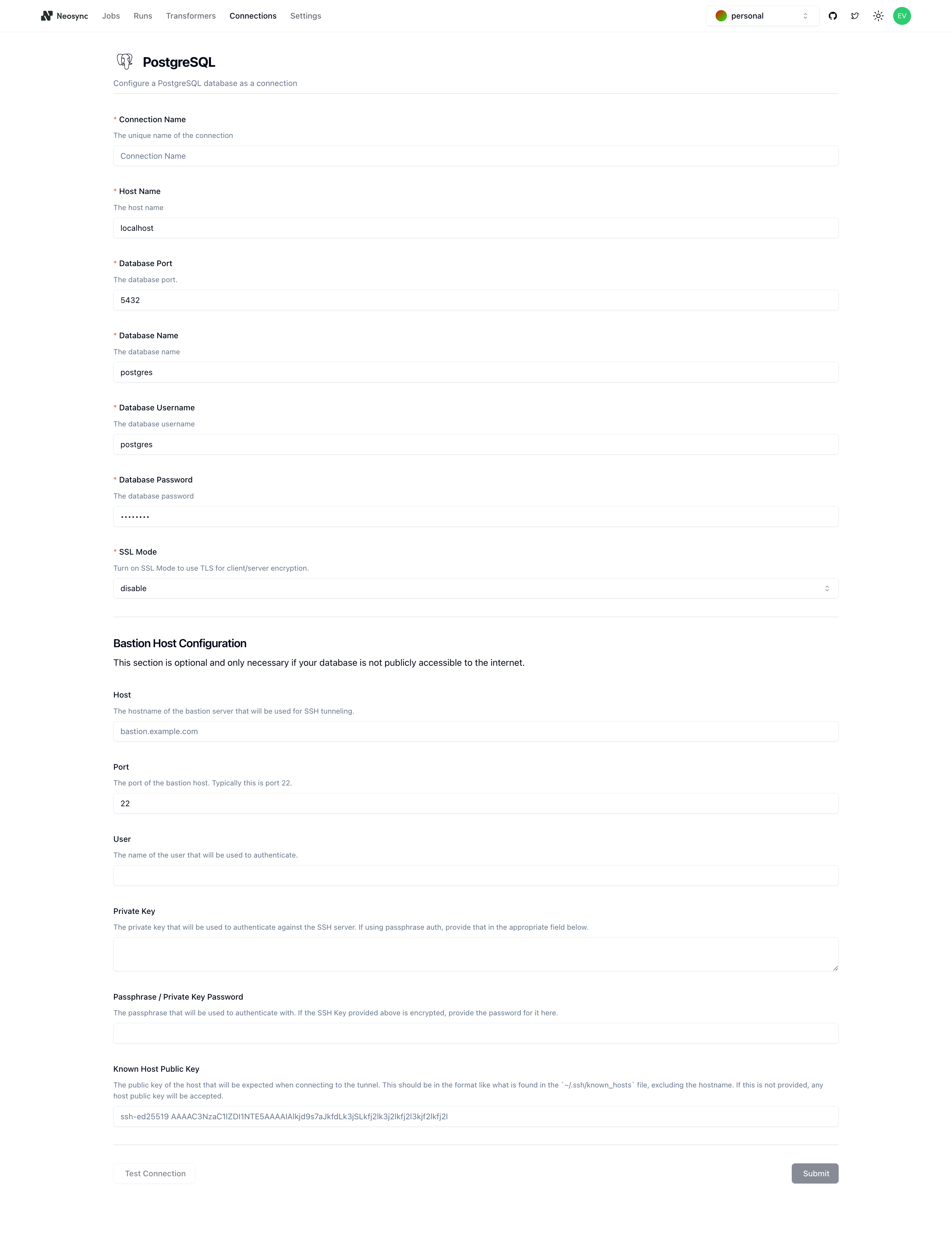
You should see the above form. Since our Supabase database is public we can ignore the bottom part about configuring a Bastion Host. Let's go ahead and start to fill out our Supabase connection string for our neosync-dest database in this form. Here's a handy guide of how to break up the connection string and map it to the fields in the form.
| Component | Value | Description |
|---|---|---|
| Host | aws-0-us-west-1.pooler.supabase.com | The hostname or IP address of the database server. |
| Name | postgres | The specific database name to connect to. |
| Port | 5432 | The postgres port that we will bind to |
| Username | postgres.aaeazfsgucgdznwvzjwk | The username for authenticating the connection. |
| Password | ************ | The password for authentication (hidden for security). |
| SSL Mode | sslmode=require | Specifies that SSL encryption is required for the connection. |
Once you've completed filling out the form, you can click on Test Connection to test that you're connected. You should see this if it passes:

Let's click Submit and repeat this for our database so that we have two connections: one for supabase-source and one for supabase-destination.
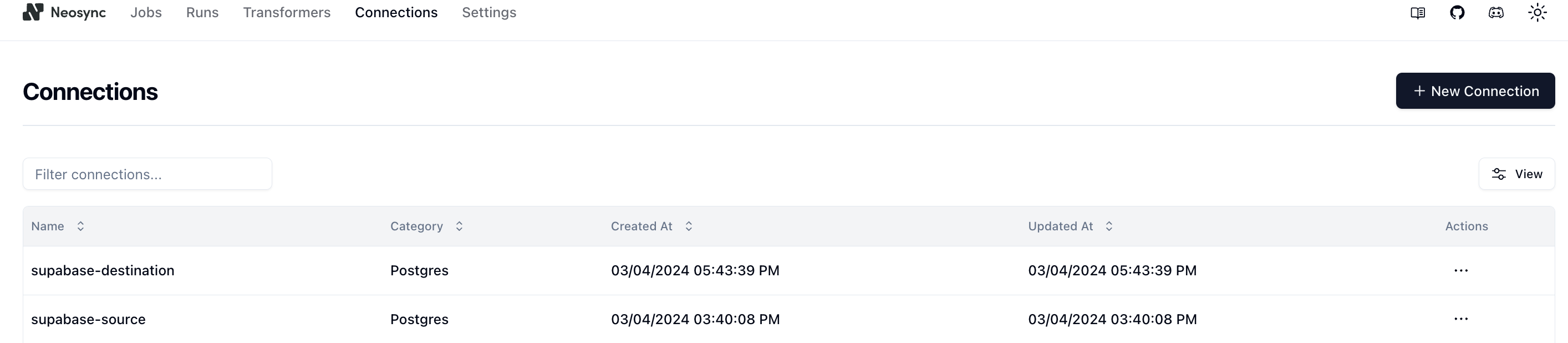
In order to generate data, we need to create a Job in Neosync. Let's click on Job and then click on New Job. We're now presented with two options:
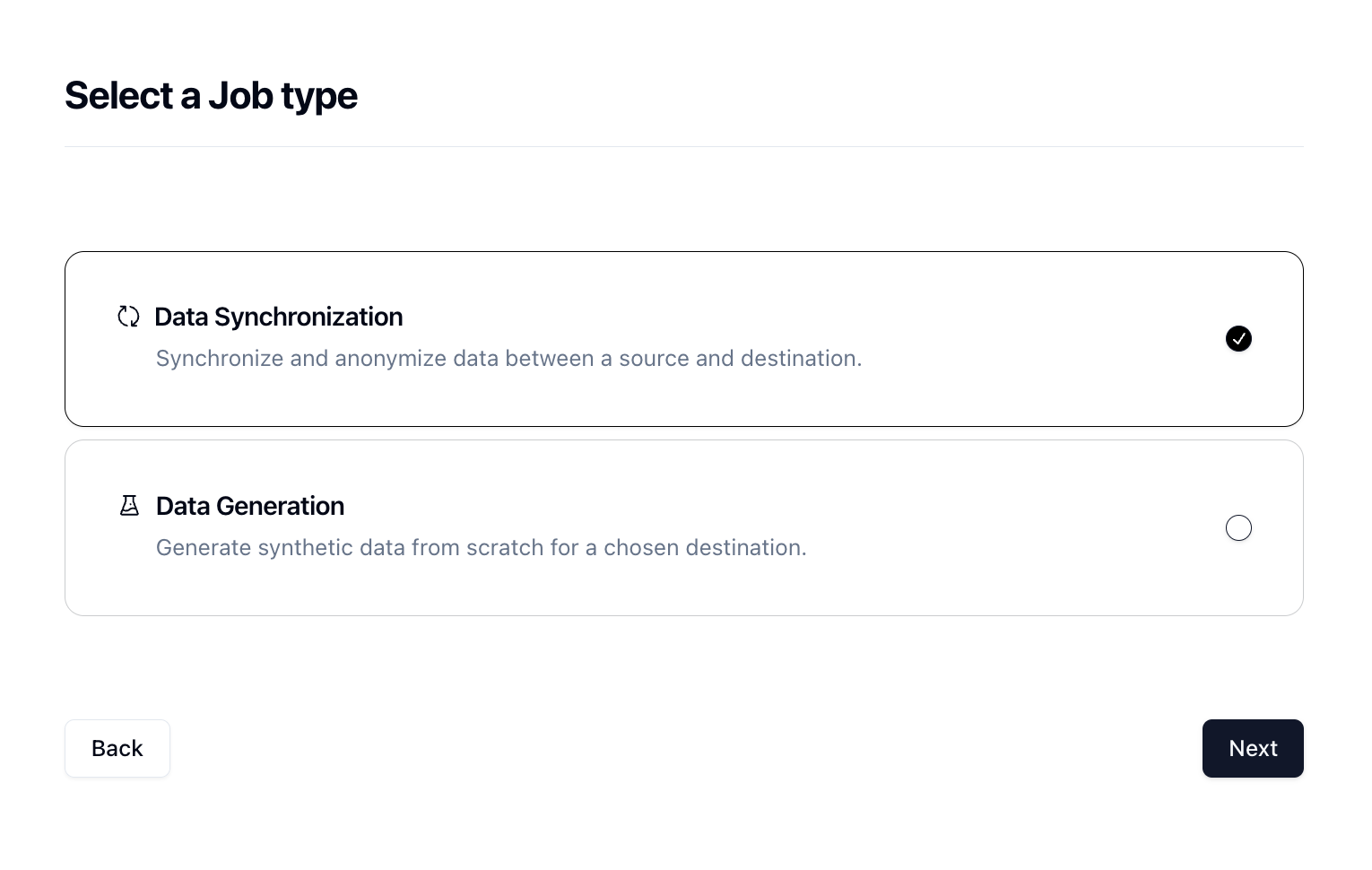
Since we're anonymizing existing data, we can select the Data Synchronization job and click Next.
Let's give our job a name and then set Initiate Job Run to Yes. We can leave the schedule and advanced options alone for now.
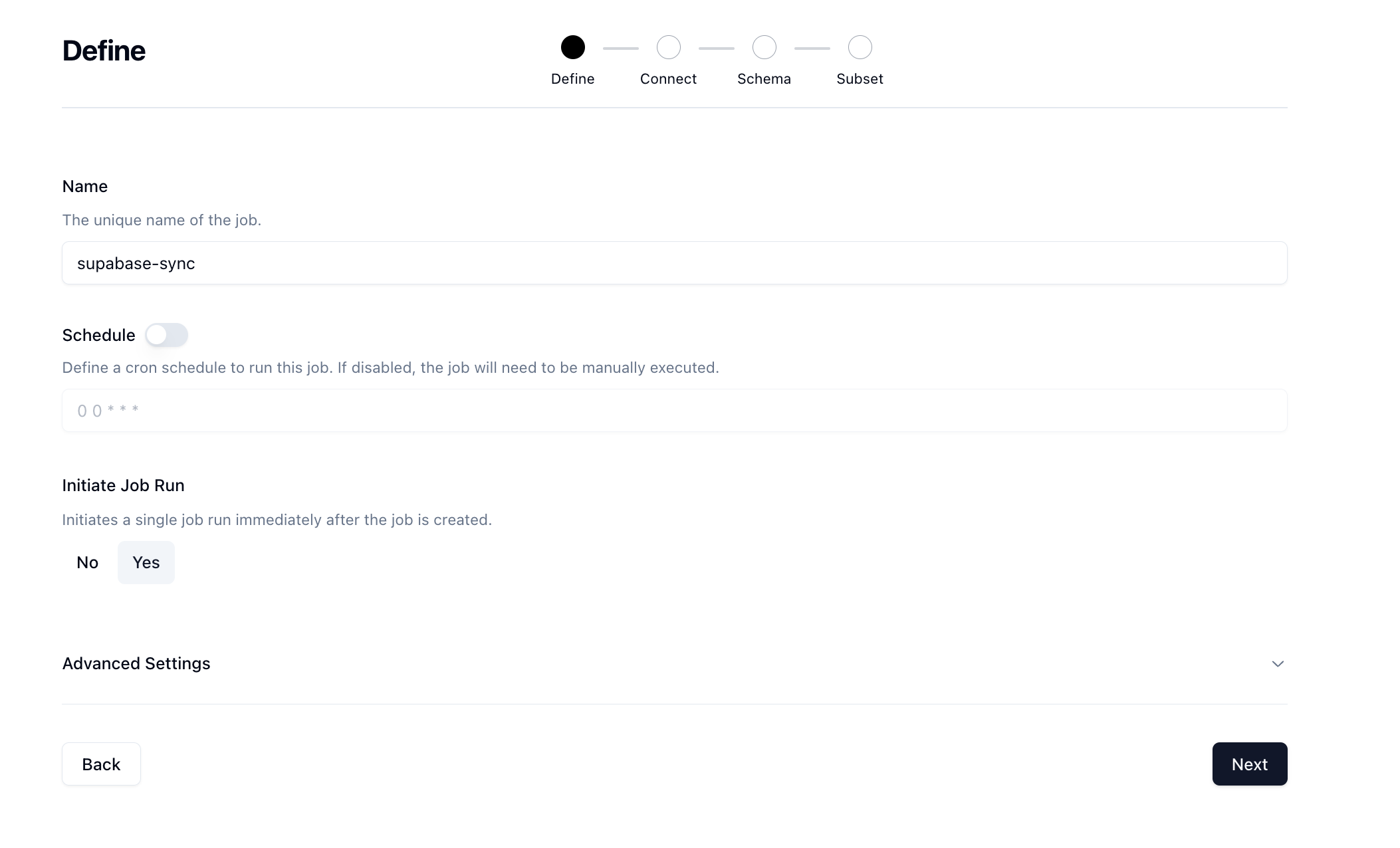
Click Next to move onto the Connect page. Here we want to select our source and destination connections that we configured earlier.
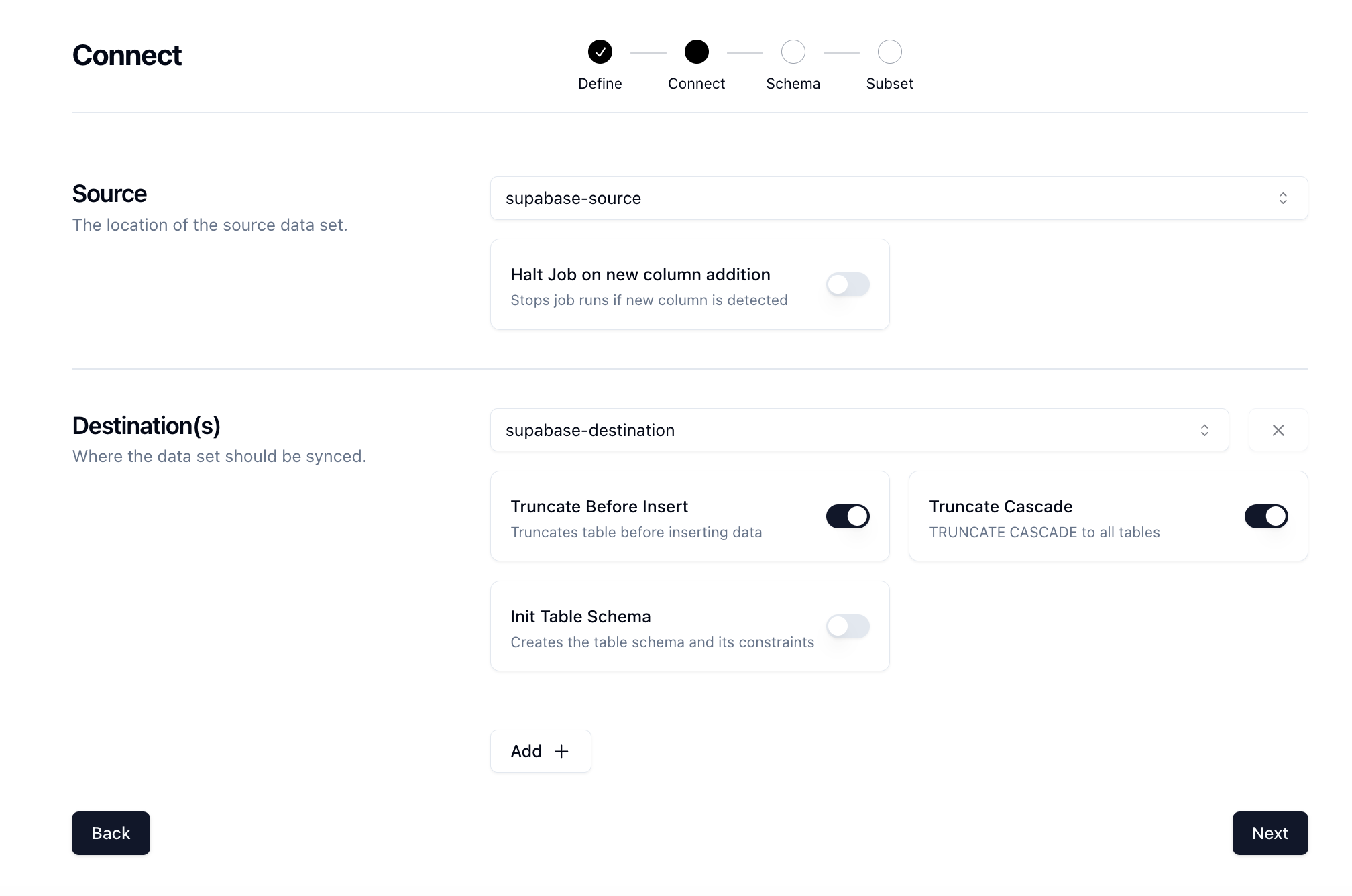
There are some other options here that can be useful. We'll also select the TRUNCATE CASCADE option which will truncate our table and cascade to all constraints so that we get a fresh set of data every time. Click Next.
First, let's filter by our Public schema and Users table.
Now for the fun part. We need to determine what kind of anonymization we want to do and/or what type of synthetic data we want to create and map that to our schema. Neosync has Transformers which are ways of creating synthetic data. Click on the Transformer and then select the right Transformer that maps to the right column.
Here is what I have set up for the users table.
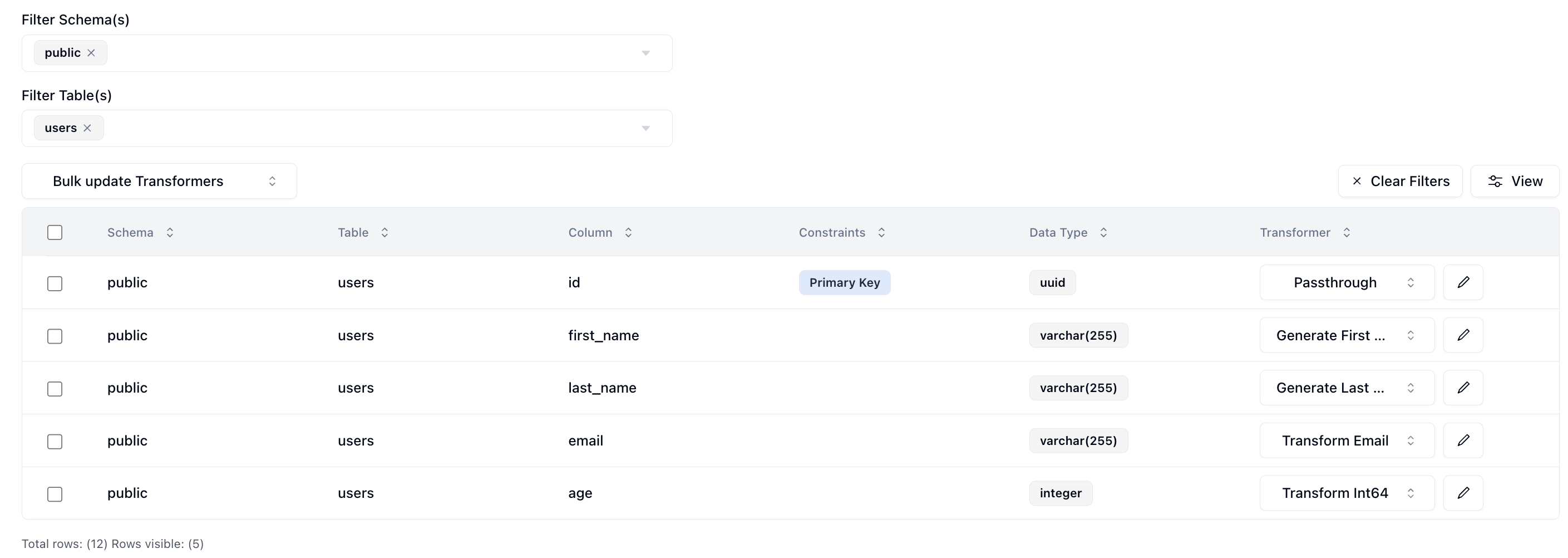
I've set the id column to passthrough which will allow us to validate our output data. The first_name column to generate a brand new first name, the last_name column to generate a new last name, the email column to transform the existing email address by generating a new username and preserving the domain, and lastly the age column to transform it by anonymizing the current value.
Now that we've configured everything, we can click on Next to go to the Subset page. We don't have to subset our data but if we did we can enter in a SQL filter to subset our data. Neosync will take care of the rest.
Now let's click Save to create our job and kick off our first run! We'll get routed to the Job page and see something like this:
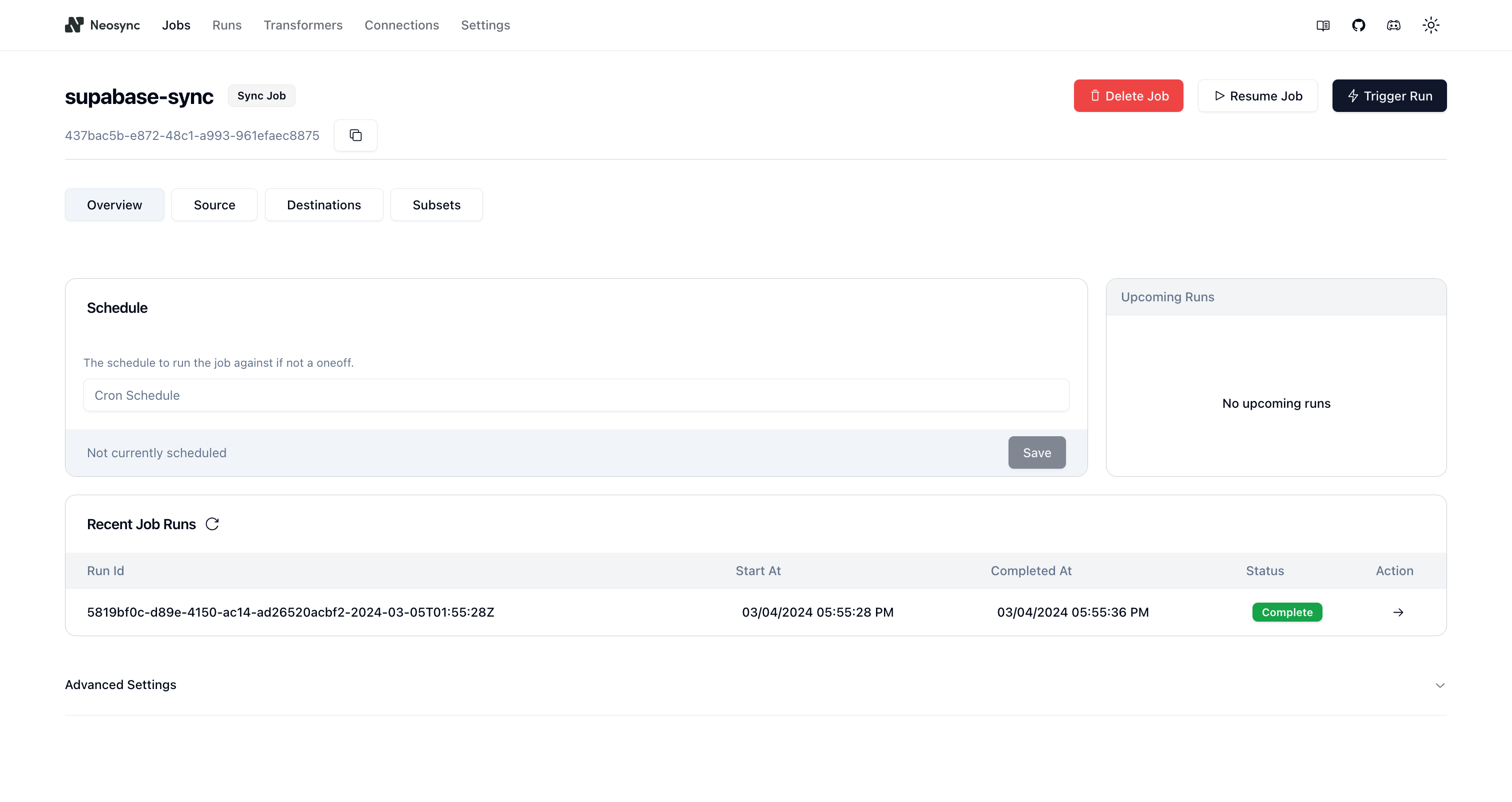
You can see that our job ran successfully and in just 8 seconds we were able to copy, anonymize and generate data from one Supabase database to another.
Now we can head back over to Supabase and check on our data. Let's check the users table. We'll want to first ensure that we generated 1000 rows since that's how many were in our source (neosync-source) database and then check that the data was anonymized and generated correctly according to our transformers.
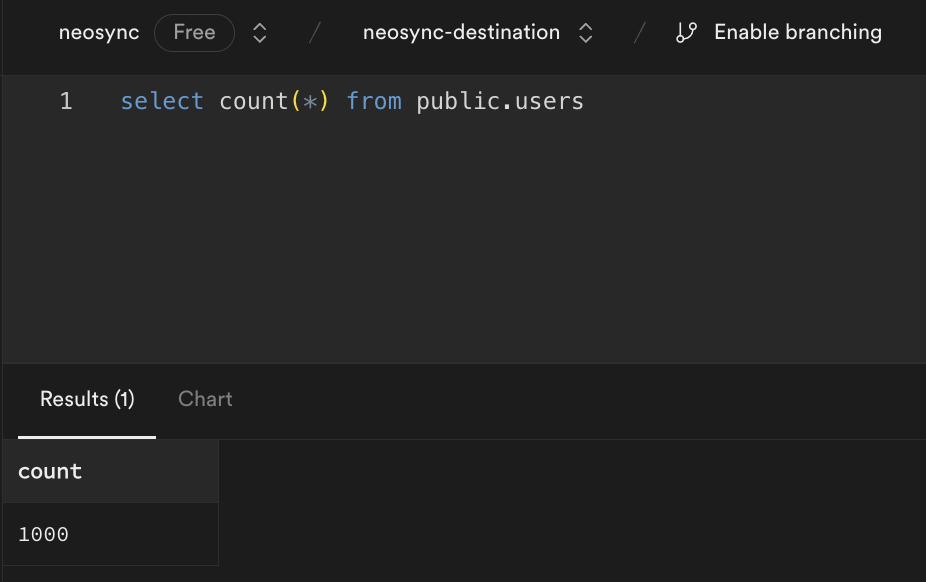
Great, count looks good. Next, let's check the data. Let's take an ID from our source and check it against the destination. Note: remember that relational databases don't guarantee order when selecting data unless you pass an ORDER BY clause so using a SELECT * FROM users query will be misleading. This is our source:
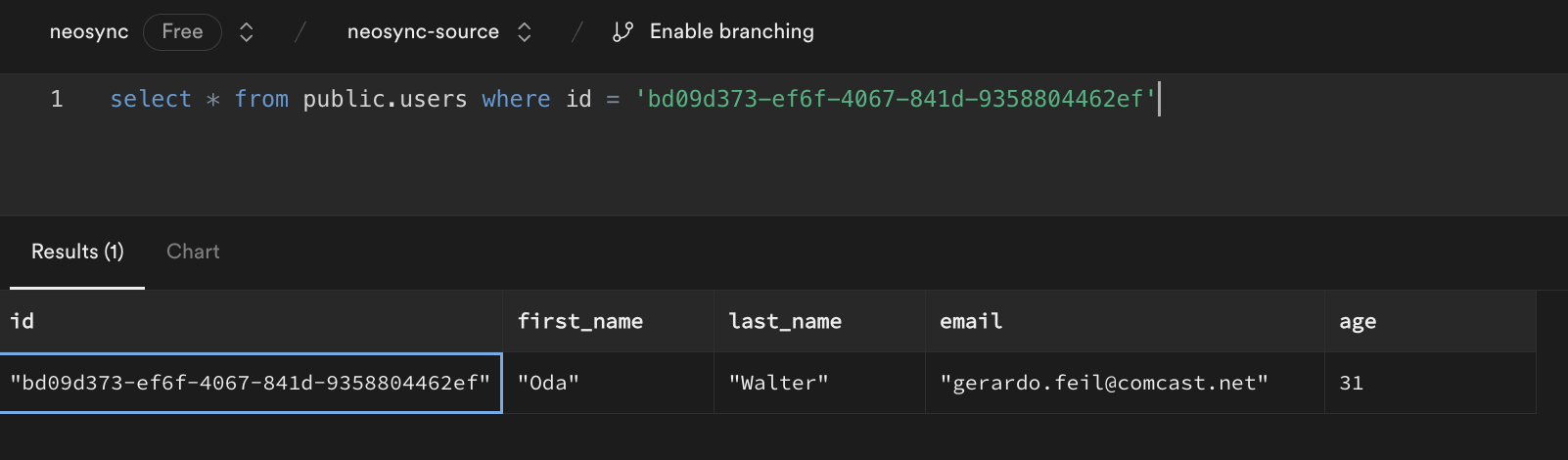
This is our destination:
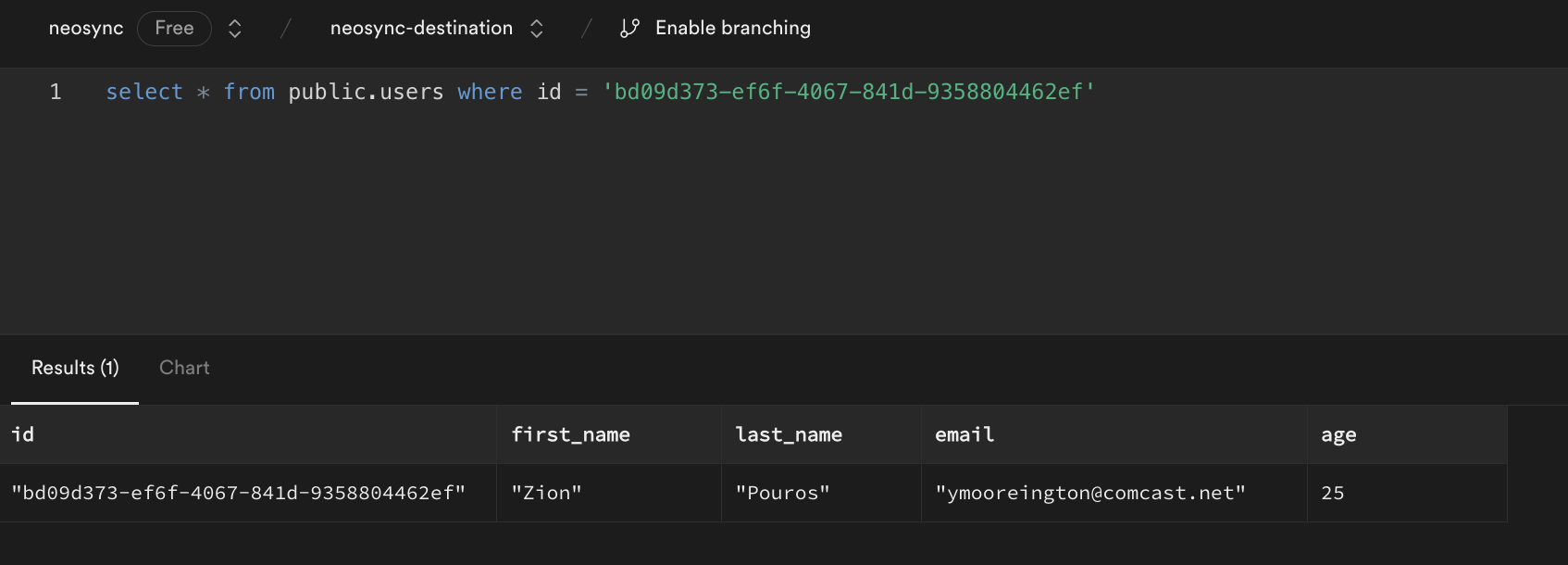
We can see that we generated new first and last names, we anonymized the email address username but preserved the domain and anonymized our age. Nice!
In this guide, we walked through how to anonymize sensitive data and generate synthetic data from one Supabase database to another. The cool thing about this is that it doesn't have to be from one Supabase database to another. Neosync supports any Postgres database. So it can be from Supabase to RDS, RDS to Supabase, RDS to Cloud SQL, etc. This is just a small test and you can expand this to anonymize millions or more rows of data across any relational database. Neosync handles all of the referential integrity. If you're working with sensitive data and want a better way to protect that data, then consider Neosync to take on the heavy lifting.
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025

Nucleus Cloud Corp. 2025