
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

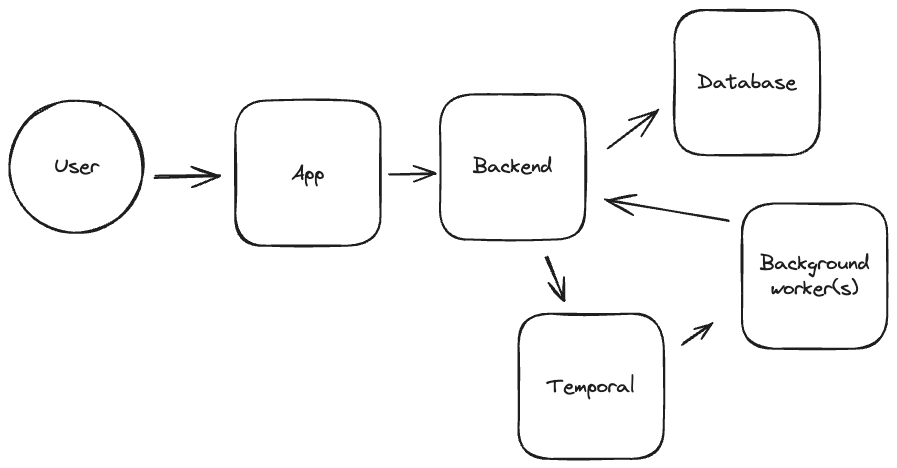
Neosync, at its core, is a workflow engine that enables two main flows: generating synthetic data, and synchronizing+anonymizing data from one data source to the next. Once a user configures these workflows, they primarily happen asynchronously and on a scheduled basis. Depending on the amount of data a user has, this may take some time. There are also constraints to worry about, which imposes a directionality to when various data frames can actually be synchronized. This post talks about how Neosync uses Temporal to enable execution scheduling these complex workflows, along with other, simpler, but fault tolerant workflows to come.
I wanted to write a blog post that touched on how we use Temporal, and why it's really important and a core part of our platform.
Temporal is an asynchronous workflow engine. Well, what is that? I think about it as an abstraction atop async, event-driven systems. As a developer, you can write a workflow that is composed of small functions that reads like an asynchronous program, but each function is effectively it's own isolated event. Each event is scheduled and is executed by a pool of workers listening to a queue. Temporal abstracts away the logic behind timeouts, scheduling, heartbeats, retries, etc and makes it very easy to write systems that easily scale.
Briefly touched on in the introduction, Neosync uses Temporal as the scheduling engine for synchronizing data between two datasources.
To make that a bit less abstract, I'm an engineer that wants to have a high-quality QA environment that the team can use to test features prior to going to production. I want the QA environment to look like production, but would prefer to not expose sensitive customer data because the access control in QA is much looser than in production. In other words, engineers have a lot more access to this environment than they might in production.
Neosync is used to sync data between production every night, but anonymizes out the sensitive data. This way, engineers can use production data, but with no risk at exposing sensitive customer data.
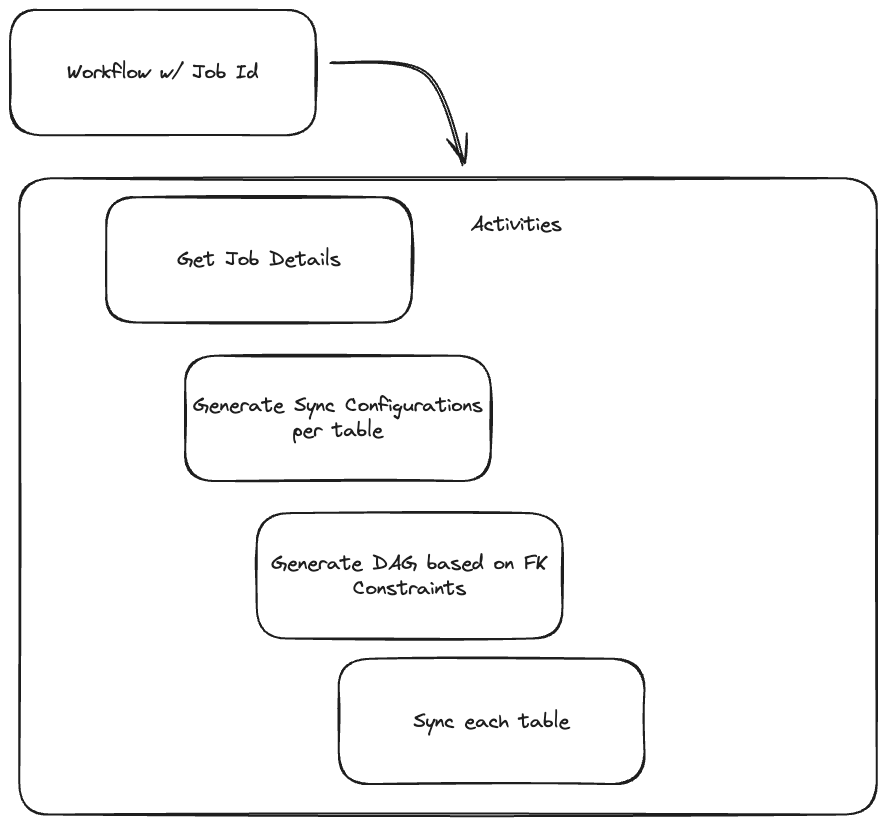
Referential data sets are effectively a graph. The algorithm is to take the data set and it's referential constraints to build a directed, acyclic graph (DAG). Once that has been done, we now have an order in which to synchronize tables whilst keeping this integrity in tact in the downstream data sources. A problem very similar to this is Continuous Integration (CI) based systems. These are DAGs that run on code commit and build, test, deploy software in a specific order, and may branch based on certain conditions being met.
Our data sync workflow that exists in Temporal is built just this way, and is a core reason why we chose Temporal over using something else like Apache Airflow. I wanted/needed something that was much more dynamic than more static config driven systems that Airflow, Tekton, etc. provided. What really drew me to Temporal was the ability to define my own domain language, and build an engine that could easily ingest that, while still having powerful guarantees and durable execution.
Once Neosync has ingested these constraints and built the DAG, this gets passed off to Temporal for execution where the workflow smartly executes table syncs in parallel once their needs have been met. It effectively walks the tree until it completes the synchronization of all nodes in the graph. This can get really tricky for circular dependencies, which you may think breaks the DAG, but we've built the workflow in sync a way that circular dependencies are managed properly. This may result in a table being touched multiple times as different patches of data are added in and updated once it's made it through to the destination.
Data syncs can take a very long time depending on a number of factors. The main one is plainly the amount of data that you have, and the second being the number of constraints present on the dataset. The less constraints, the faster we can sync due to the higher level of concurrency that can be achieved.
Due to jobs taking potentially a long time, failures or errors are bound to happen. Temporal again makes this easier by having retries and failure recovery built into the system itself.
How your workflows handle recovery are up to the workflow author of course, but Temporal provides a nice system out of the box that makes it the job of the developer to simply figure out what to do when a retry needs to happen, and not build the system for it as wel.
Neosync creates a separate Temporal activity per table (in the simple case). Today, if a worker dies or a retry needs to happen, it simply starts syncing the table again. This could result in errors too if data had already been inserted, but we offer the ability to do nothing on conflict so that any existing data in just untouched.
In the future we plan to build deeper checkpointing so that it doesn't have to start from the very beginning if a worker restarts for whatever reason.
Without Temporal's ability to give us retries, syncing a database would be very difficult in the event of a reboot or failure as Neosync would have to keep track of what it has and hasn't done in its own system code. With Temporal, this is tracked automatically for you and Temporal gives a very clear history graph of what tables have completed, and how long they took. You can even replay the order again if you want! It's great.
In this section, I wanted to touch on a few other designs that I had considered when first architecting Neosync, and had even built various proofs of concept for, before ditching them to go with Temporal.
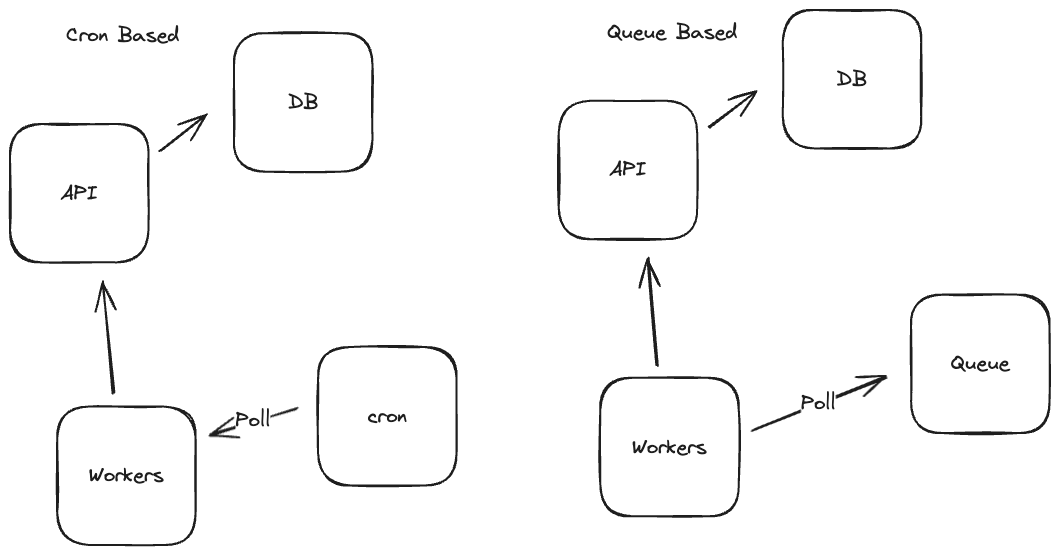
Poll-based systems are those that are either a) always online or b) wake up periodically, to check for some work to do. This involves a queue of some sort. How items land into the queue is not really of concern to these workers.
I've built plenty of event-driven workflows in the past. These always used some broker, queue setup. Whether it be RabbitMQ, SNS/SQS, NATS, or something else, they are all primarily the same, or at least fall into a similar category. Some of them offer varying levels of guarantees, retries, etc. Some of it is left up to the user to implement themselves.
These systems are great and work well for many organizations. It can get a bit wild however when it comes to the number of states that these workflows can be in when it comes to recovery, retries, ensuring no duplicate work, etc. I had considered going with something like this, but was hoping to not have to build so much from scratch like I had to do in the past. This almost always involves a technology choice anyways, and I wanted something open-source, batteries included.
There are a ton of options on the market and it can be very difficult to make a choice, especially an infra choice that might have lasting implications on your organization. Being a startup, going with Temporal is a big choice, but is a technology that can be used small or big. It's a technology that we will likely never grow out of and will continue to grow with Neosync.
I liked that Temporal was primarily code-based and you didn't so much how to worry about the transport layer and can just describe your entire pipeline in a single workflow function. This was pretty powerful and a nice departure from the heavily distributed nature of something like SNS/SQS.
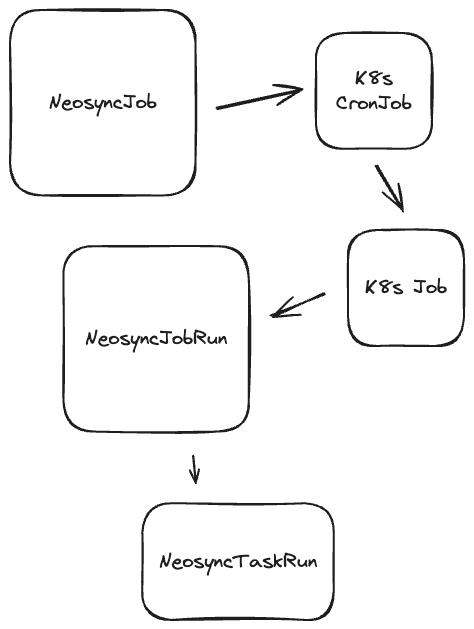
A Kubernetes Operator is about as cloud native as it gets. These operators live inside of a Kubernetes cluster and are in charge of reconciling resources that they own. When someone creates a new resource that an operator is in charge of, this kicks off a reconciliation loop that can involve a variety of things. Those not familiar with Kubernetes can simply think of this as a custom REST API encoded directly into Kubernetes.
My original proof of concept involved a custom NeosyncJob resource that, when combined with a NeosyncRun, would take the job's manifest, and kick off the necessary Kubernetes Job's to execute the table synchronizations. The NeosyncJob itself was backed by a Kubernetes CronJob that allowed it to spawn these Run's on a schedule. This, for the most part, worked pretty well. However, it had its limitations, primarily that you had to be using Kubernetes if you wanted to install Neosync and run it yourself.
After I built an initial working concept of this, I ditched it because internally we decided that it might be better to not pigeonhole ourselves into Kubernetes land and to build something that could be deployed anywhere, even if that place happened to be Kubernetes.
This set me off in search of some better orchestration software that didn't rely on Kubernetes, but was open source and could be deployed anywhere, which eventually led me to Temporal.
At Neosync, we plan to further utilize Temporal for most async jobs/workflows that it needs. From enabling a notification system, webhooks, timers, and more. This all can be done by using Temporal instead of having to write all of this yourself. We can continue to write these workflows easily and simply plug them into the running engine.
With AI, Temporal has support for a few different SDKs, so as we further integrate AI Models our synthetic data side of the platform, we can write our workflows in Go, but offload the actual training/sampling to Python-specific queues to do the work they need to, which will be isolated to GPU-enabled machines.
As we expand our usage of Temporal, I plan on further taking advantage of using Temporal as an API/Backend by implementing usage of Temporal Signals and Queries. This allows state to effectively live within a Workflow and be modified/queried in such a way. There is also protoc-gen-go-temporal, and awesome protoc plugin that makes describing Temporal APIs much cleaner!
service DataSync {
option (temporal.v1.service) = {
task_queue = "data-sync"
};
rpc SynchronizeDatasets(SynchronizeDatasetsRequest) returns (SynchronizeDatasetsResponse) {
option (temporal.v1.workflow) = {
id: '<job-id>',
query: { ref: "GetSyncProgress" }
signal: { ref: "SetSyncProgress", start: true }
};
}
rpc GetSyncProgress(GetSyncProgressRequest) returns (GetSyncProgressResponse) {
option (temporal.v1.query) = {};
}
rpc SetSyncProgress(SetSyncProgressRequest) returns (SetSyncProgressResponse) {
option (temporal.v1.signal) = {};
}
}
message CreateDataSyncRequest {
string job_id = 1;
}
message CreateDataSyncResponse {
Job job = 1;
}
message Job {
string name = 1;
...
}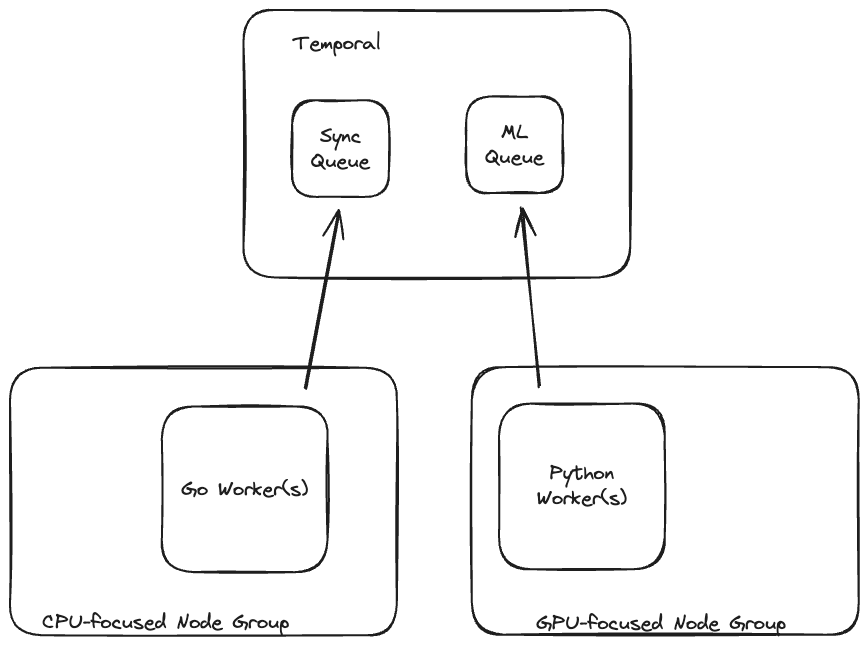
AI Generation is something we do today at Neosync with LLMs. We'd like to allow bringing our own models in the future and let the worker query those models, possibly directly. Temporal allows workers to exist in multiple different languages, which is pretty great! You can have a single workflow span Go, Python, Typescript, etc, just like a standard microservices setup. All that needs to happen (at least today) is to have those language-specific workers running on their own queues.
This polyglot workflow setup is really powerful and will someday power Neosync AI capabilities where users can bring their own models that Neosync can run. Along with Neosync running its own models in the cloud variant.
That's it! This post dives into how we're using Temporal at Neosync, along with some of the history that led me to that decision. Temporal is a powerful platform that enables easier microservice and async, event-driven development in a way that primarily just works. They've clearly thought deeply about this pattern and have built a system that enables this generally, without you as the developer having to worry about the gritty details around scheduling, statuses, and more. It is up to you how you want to handle retries in terms of what to do if piece of work fails partially through and how it can recover in a graceful way, but Temporal will make it easy for you to handle this states, leaving you to focus on recovering in your business logic, without having to build a system that even allows that in the first place.
The full code for our Data Sync and Generate Workflow can be found here: Workflow
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025

Nucleus Cloud Corp. 2025