
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

From the beginning, we've built Neosync to be developer-first and to fit into any developer workflow. And many of our customers use Neosync as part of a gitOps pipeline, or within git-based workflows where everything is checked into code.
One thing that has always been a little too manual for our liking was creating Job Mappings. Now, you can quickly configure your Job Mappings in the Neosync UI and then export them to a file and check them into your version control system.
Let's dive a little deeper.
When you create a Job in Neosync, you configure your schemas, tables and columns to define exactly what you want to anonymize and how you want to anonymize it. You do this by mapping Transformers to your columns.
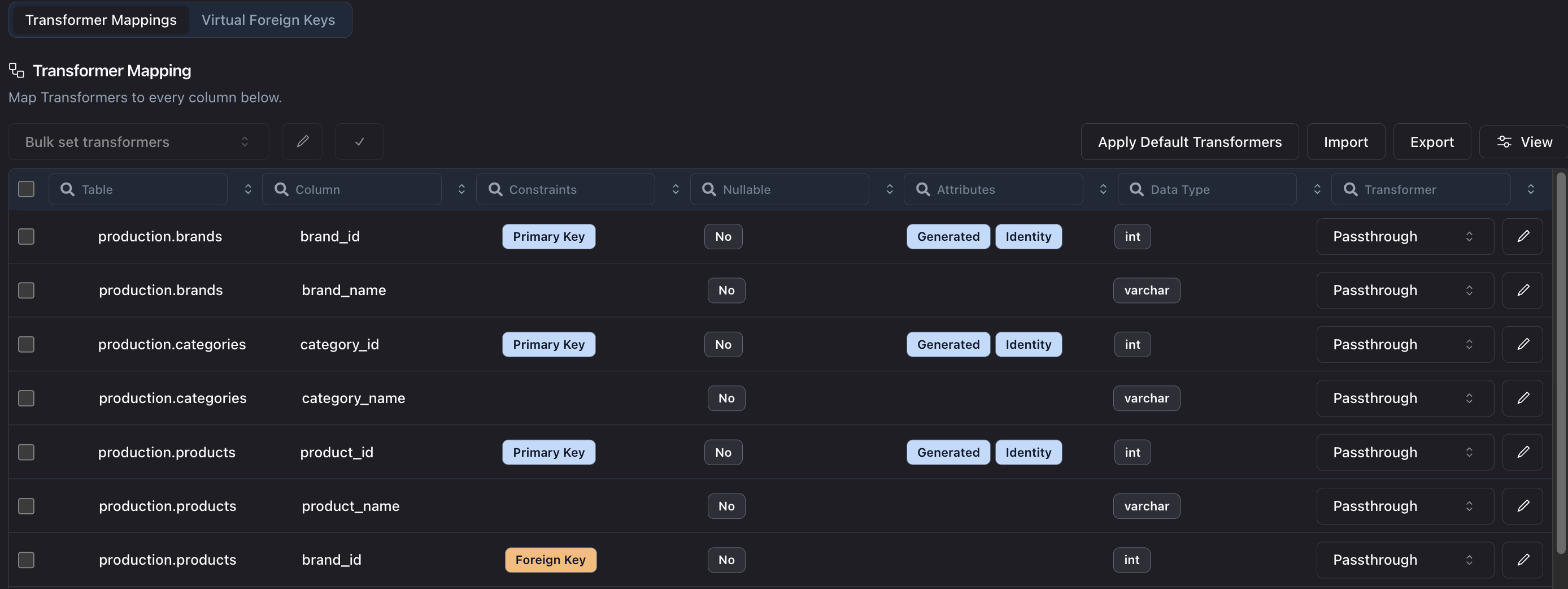
In the screenshot above, we've mapped the Passthrough Transformer to the brand_id column in the brands table in the production schema. These Job Mappings are the core of the job and tell Neosync how to treat the data in each column.
You can also have Transformer Options as part of the Job Mappings which are parameters that configure the Transformers.

For example, the Generate Random String Transformer takes in min and max length parameters to determine how long of a random stirng to generate.
Let's take a look at what the underlying data structure looks like when we want to export this data.
In order to export your Job Mappings, simply click on the Export button in the Transformer Mapping table. You will then be prompted with a modal and asked if you want to format and prettify the JSON in the output.
Let's look at the output.
[
{
"schema": "production",
"table": "brands",
"column": "brand_id",
"transformer": {
"config": {
"passthroughConfig": {}
}
}
},
{
"schema": "production",
"table": "brands",
"column": "brand_name",
"transformer": {
"config": {
"passthroughConfig": {}
}
}
},
{
"schema": "production",
"table": "categories",
"column": "category_id",
"transformer": {
"config": {
"passthroughConfig": {}
}
}
}
]The output is a json array of objects which have fields for the schema, table, column and transformer. And in this case, since the transformer is set to Passthrough, it uses the Passthrough config.
Let's add in the Generate Random String Transformer and fill in the min and max parameters to see what it looks like when we configure a Transformer.
[
{
"schema": "production",
"table": "brands",
"column": "brand_id",
"transformer": {
"config": {
"generateStringConfig": {
"min": "2",
"max": "7"
}
}
}
},
{
"schema": "production",
"table": "brands",
"column": "brand_name",
"transformer": {
"config": {
"passthroughConfig": {}
}
}
},
{
"schema": "production",
"table": "categories",
"column": "category_id",
"transformer": {
"config": {
"passthroughConfig": {}
}
}
}
]Adding in Transformer options change the field in the config object and filled it in with the parameters.
You can now check this into your version control system and manage your mappings directly in code!
Importing your mappings is just as easy as exporting your mappings. Simply click on the Import button and drag-and-drop your files into the modal.
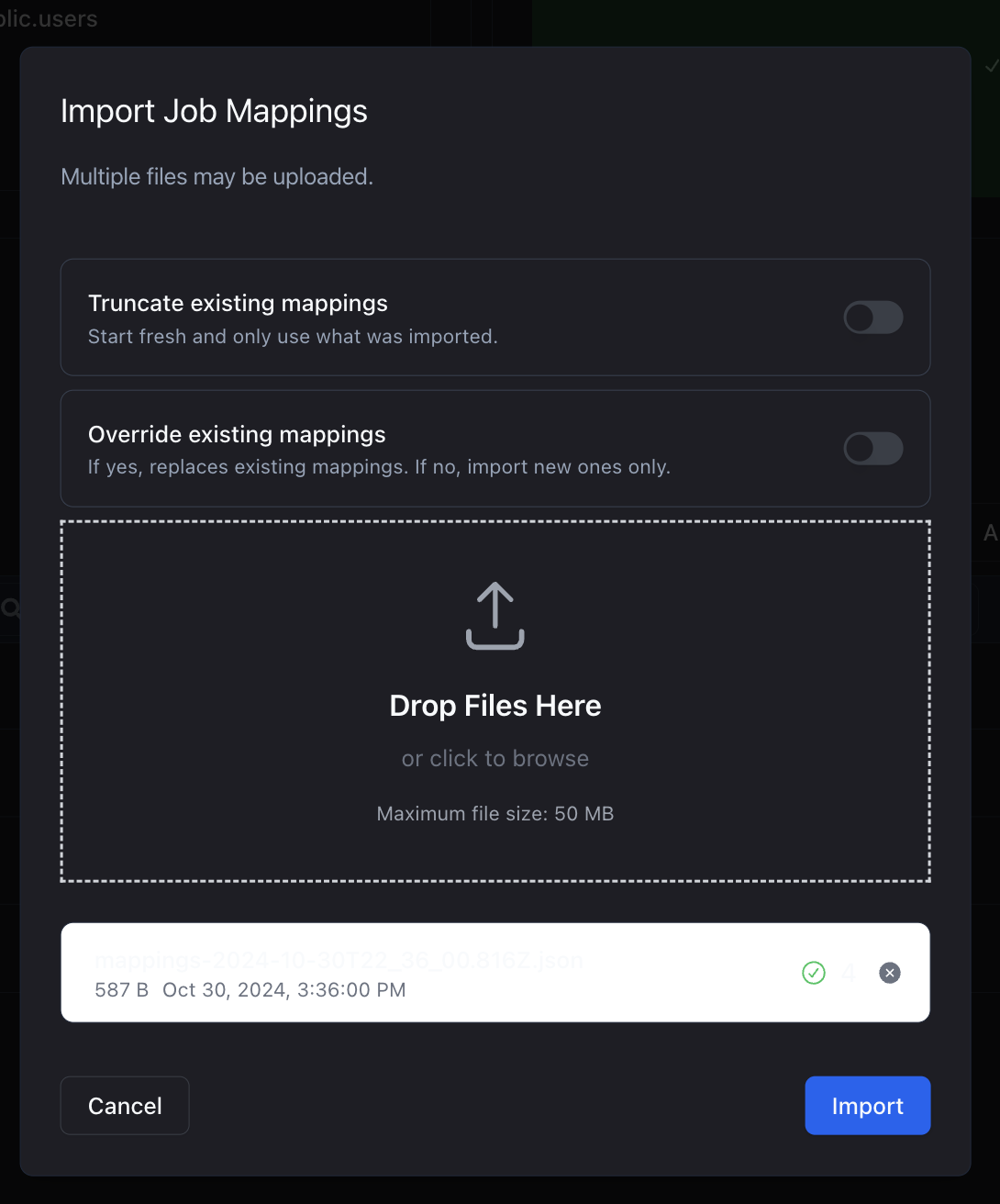
You also have options to truncate your existing mappings or override existing mappings. Once you've configured your settings, you can click on Import to import your files.
Easy as that.
We're excited for you to try out this new feature and looking forward to hearing feedback on how we can continue to further improve it.
Happy building!
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025

Nucleus Cloud Corp. 2025